
Recently I had the chance…actually the need to have a look into how a given PDF manages its images. Here I’ll explain what the initial issue was an the findings along my journey. Disclamer: This is written more like a logbook / narration than an actual article.
Last week I started reading the online material for my PADI OWD (Open Water Diver) course. Yes…now you realize this post title is very pun-intended, anyway… To my surprise the content had quite a bad responsiveness. Some images failed to load, others disappeared if I scrolled up and down. Here’s a tweet showcasing the issue
Not only that, but the page requested the images more than once, making it even slower. All these made me wonder how this was made and if it could be improved in any way. So, into the browser’s dev tools we go.
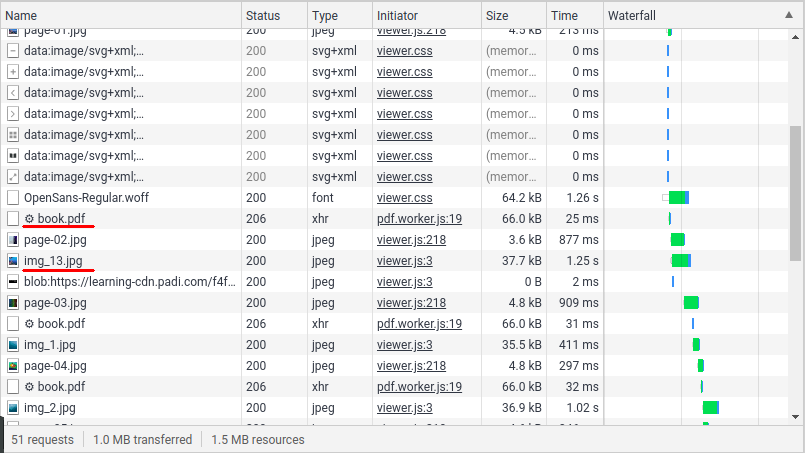
The first two interesting elements are a book.pdf and a set of img_X.jpg which are the images that are shown in the document. Let’s first try to open the PDF and see how it is.
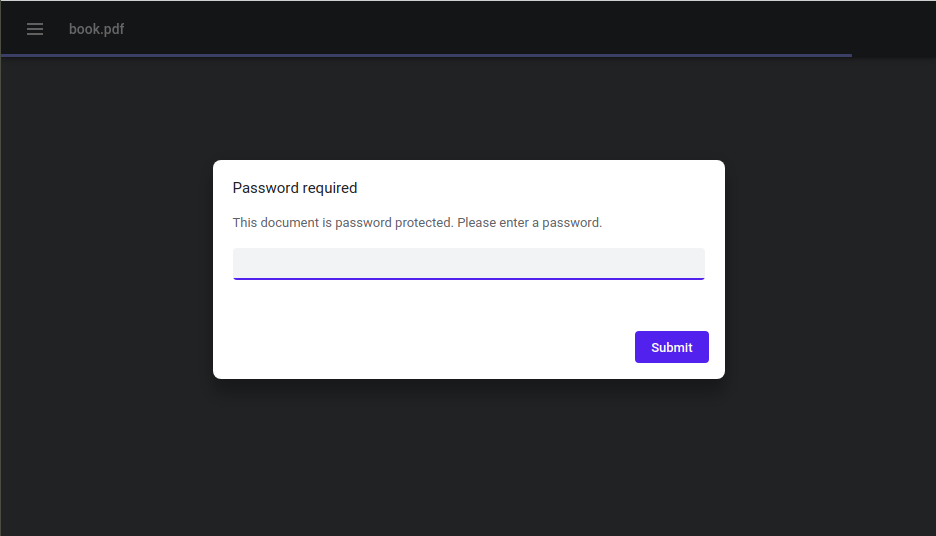
The document is password-protected, however since the viewer is able to show the document without asking for any password we can assume the password is accessible to the client-side at some point. Let’s continue browsing the resources.
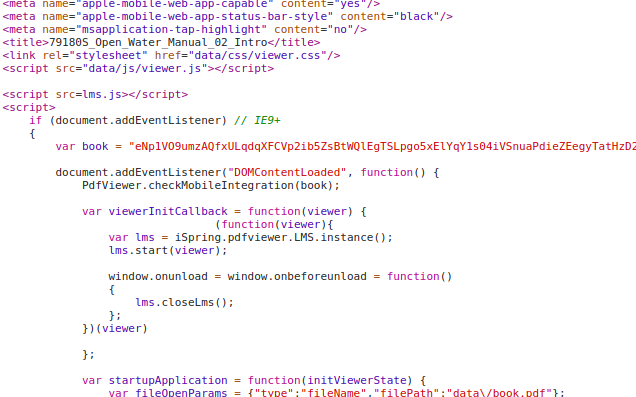
In the index.html two things caught my eye.
- The book variable containing b64 encoded data than is then passed to a PdfViewer method
- There is something called iSpring which seems to be the viewer.
Let’s first add a breakpoint in the mentioned method
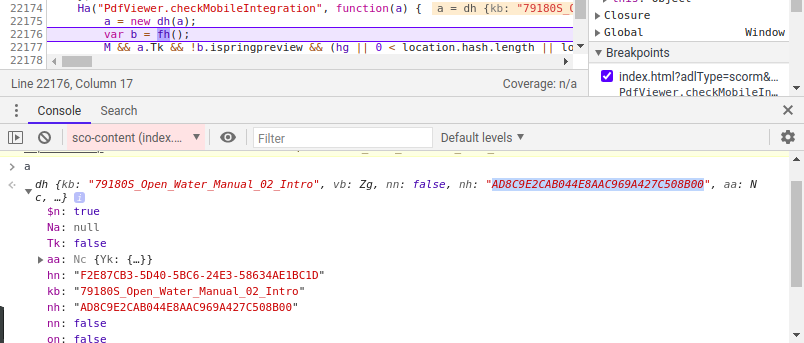
The first thing done by the method is create a new instance of an object, using the b64 code. Inspecting the object’s attributes we can see something resembling a document name (“Open Water Manual 02 Intro”) and other strings. After trying some, I found out the nh attribute was in fact the document password.
However we do see there’s something odd… The document lacks any images, what I deduce is the viewer loads the PDF and then loads the images dynamically as we scroll through the document. This arises some questions.
- How does the viewer know which images to load and where to put them?
- Is there any way to revert the process and obtain the original PDF?
However, I don’t want to keep fiddling around with this document / page to avoid any ToS / Copyright infringement. Luckily the very same html page does provide a hint which I previously mentioned, the iSpring name. After some googling I found the following
It seems the document viewer is called iSpring Flip and fortunately they do offer a trial version of their product.
I used the software with one of my physics assignments, which you can check here. iSpring gives you a folder with the following contents
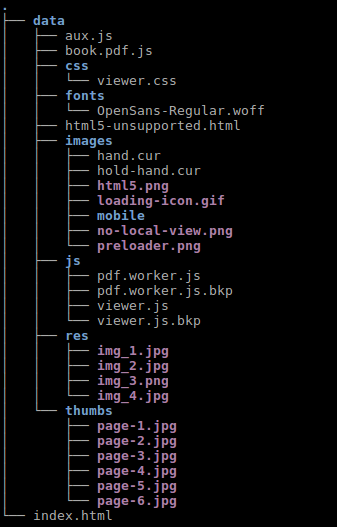
The images contained in the res folder are indeed the images embedded in the pdf.
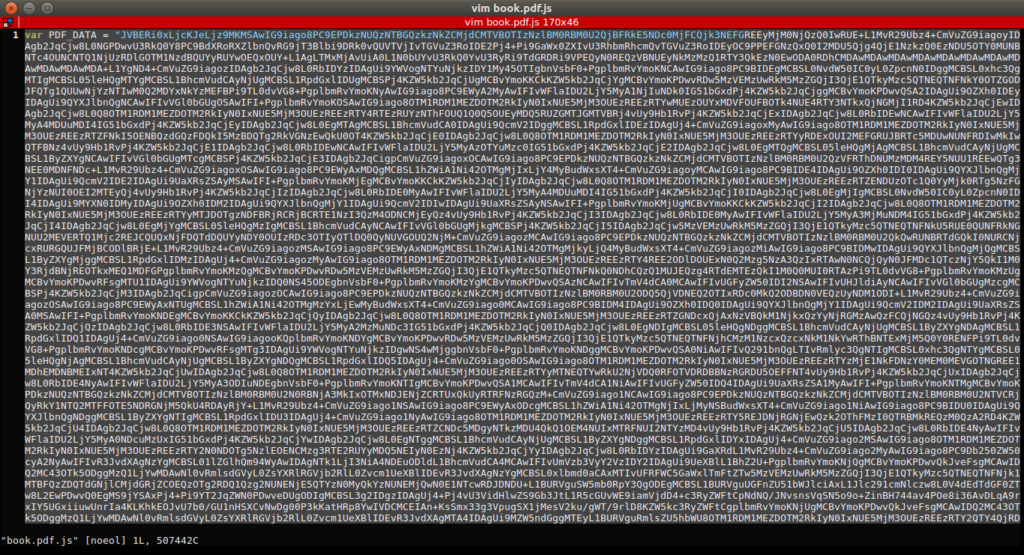
There’s also a files named book.pdf.js and taking a look into it we find the following
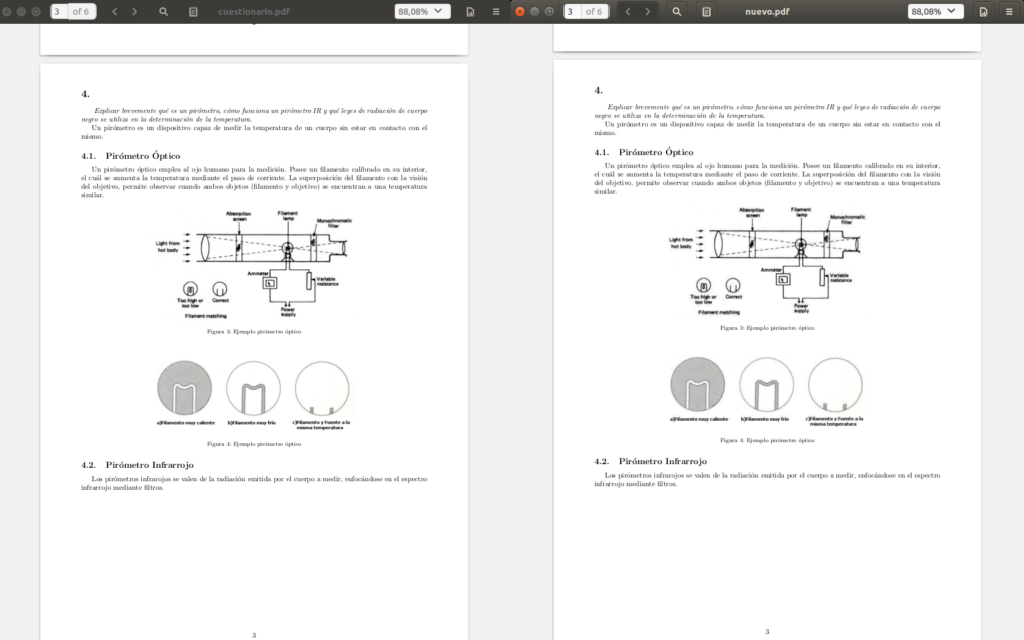
I decoded the b64 into another file and opened it, finding a password protected PDF. Using what I’ve learned above I found the password. This is a comparison between the original PDF and the pdf found in the resources, where we can see the lack of some images.

I opened the pdf file with a text editor and searched for any reference of a “img_x.jpg”. NOTE: The original PDF is compressed which makes inspecting its contents harsh. I used the qpdf tool to decompress it.
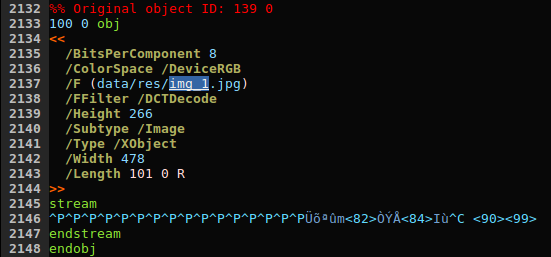
The first result we see some kind of object with a reference to an image (with the correct path), some attributes such as height and width (which matches the actual image size) and some sort of stream.
Taking a look into the pdf specification we can find the following definition:
An external object (commonly called an XObject) is a graphics object whose contents are defined by a self-contained stream, separate from the content stream in which it is used.
It looks like we can include an image just by including its stream into the stream / endstream block, so let’s test it. I opened a Jupyter Notebook and started fiddling around, ending up with
[gist]https://gist.github.com/aleperno/33a61a582d53edfd736686fe0e9292a7[/gist]
This code basically does the following
- Finds every object of type XObject and subtype Image
- Checks it contains a property F matching ‘data/res’ and retrieves the image name
- With the image name tries to obtain the image from a given folder and set the stream into the file.
And as a result we obtain a PDF with images just like the original one
Learnings
PDFs has a simple way to include images by including an stream, it is also allows us to use the same image multiple times without duplicating the stream but rather using references to the object.
Also by them being streams, we can extract images, modify them and re-add them to the file without much hassle, this could be useful when trying to reduce a document size, we can try to compress the images.
An important side-note is by being streams, images conserve metadata which could be “dangerous” by enabling anyone to extract the images EXIF info.